Hash Tables
Hash tables (or hash maps) are data structures that store data in arrays according to that data’s key.
Parts of a Hash Table
There are two main components to a hash table:
- Hash functions take in a key value and return an array location to store the data.
- An array to store the data.
A good hash function minimizes the number of collisions by uniformly distributing the hash values.
Collisions
Collisions happen when a hash function returns the same array index for two different keys.
There are a couple of ways around this issue:
- Chaining: Create an array that stores linked lists. Whenever a collision happens, append new data values at the end of the linked list for that index.
- Linear probing: Find the next open spot and put the data there.
- Increase size: Make the array bigger so that collisions are less likely.
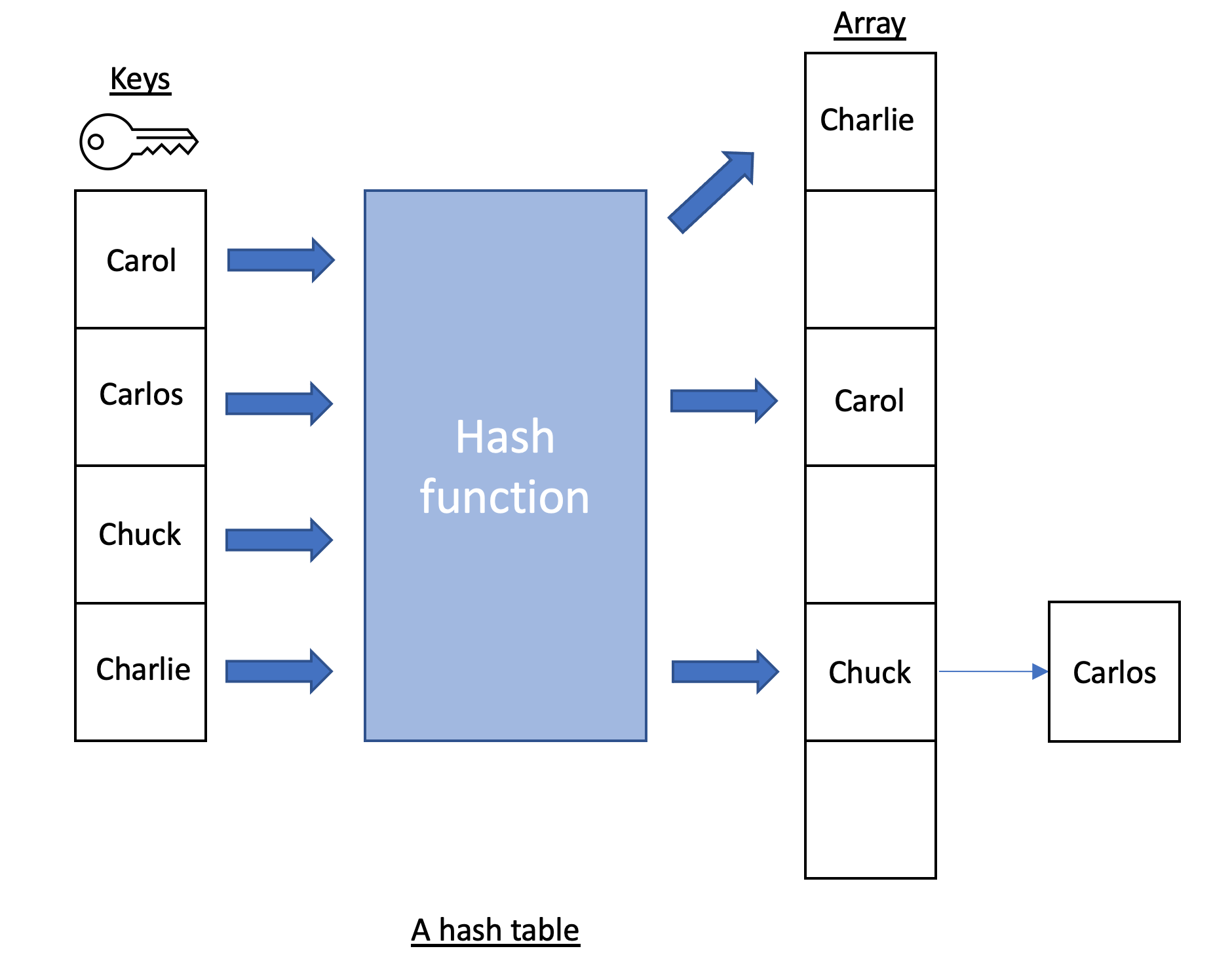
In the image above, the keys Carlos and Chuck were put in the same array location. A linked list was created so that Carlos could be put in the array.
Pros and Cons
Pros:
- Search, insert, and delete functions run in constant time, on average.
- If the hash table uses chaining to resolve collisions, the size of the hash table can increase while maintaining rapid access speed.
Cons:
- If there are too many collisions, then the hash table becomes less efficient.
- For small amounts of data, an array or a linked list is usually faster.
Time Complexity
In the worst-case runtime, search, insert, and delete functions have a time complexity of \(O(n)\). However, a well-implemented hash table tends towards average time complexity.
Insert average time complexity: \(O(1)\)
Delete average time complexity: \(O(1)\)
Search average time complexity: \(O(1)\)
More Resources
Below are some more resources to learn about hash tables: